Offical documentation
Parallelisation
The easiest way to speed up CI builds is to split your tasks up to be run in parallel on multiple machines. Parallelising your workload means that you are only limited by the slowest step in your build. Think about things that don’t immediately look like they could be run independently verify that assumption – Knowing your dependency graph inside-out is going to help a lot.
What is “sharding”?
In distributed computing, we talk about splitting up a process across multiple machines. To do this, we separate a workload into “shards” of deterministic tests/actions. In CI, it often means batching all of our unit tests into X number of shards, which will then be run concurrently.
Popular patterns
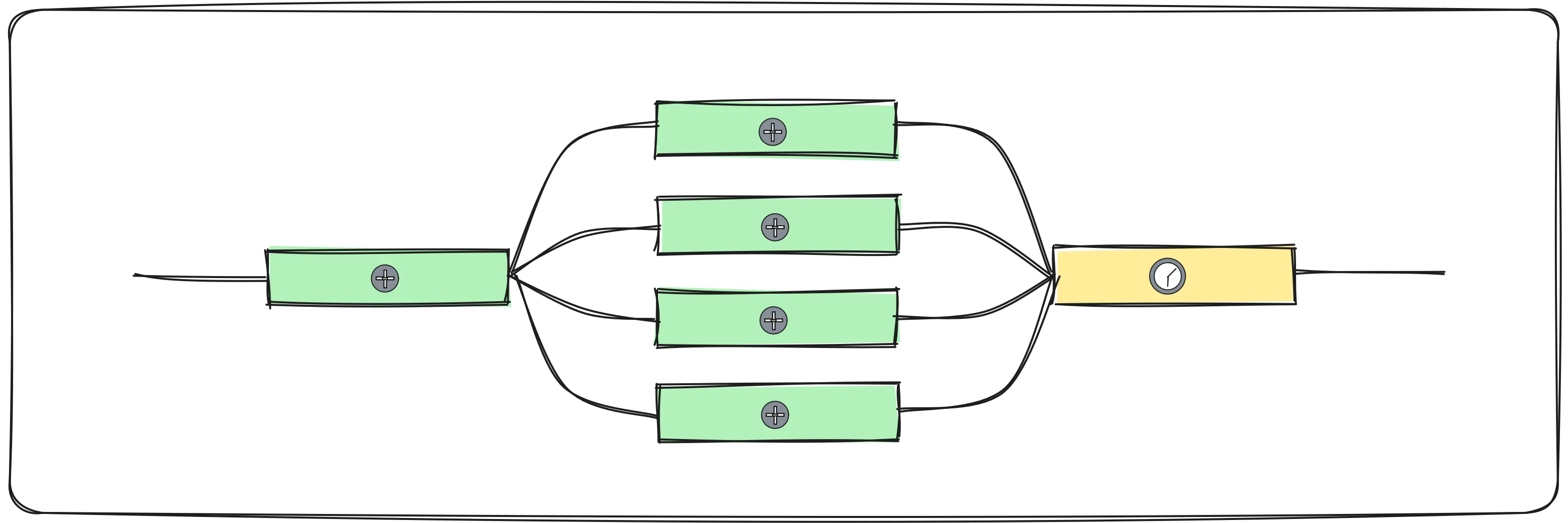
Fan-out/Fan-in
This pattern involves running a common build/compilation step to setup the code for testing, then fanning-out run a set of acceptance tests in parallel and then fanning-in again to run the deploy job.
Trading space for time
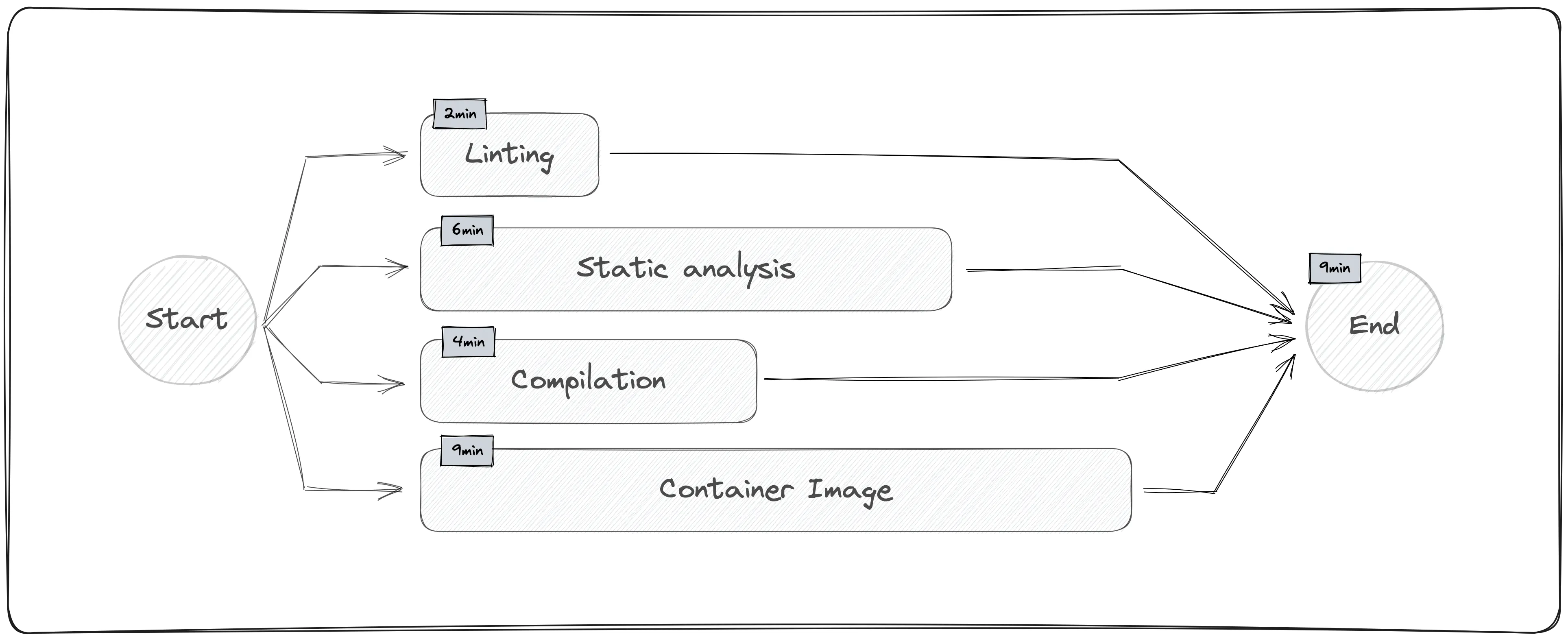
You can make a trade-off here to parallelise things that generate artefacts, by trading storage space for speed. Yes, if the build fails, the artefacts aren’t useful but if you can spare the storage space, and handle cleanup/archival on a fixed schedule elsewhere, you can save time by not requiring code correctness before you start building the artefacts. If the docker image build takes 5 minutes, and the full static analysis suite also takes 5 minutes, waiting for the analysis feedback before building the docker image costs you time.
Test Sharding
Node - Cypress
Cypress can parallelise tests across CI machines using the CLI.
cypress run --record --parallel --ci-build-id $BUILD_TAGNode - Jest
The Jest CLI takes a --shard flag that can split your tests and let you run
different sets of tests of different machines.
jest --shard=1/3Python - pytest
This uses the pytest-shard library to implement sharding in pytest.
pytest --shard-id=0 --num-shards=2How to for CI providers
CircleCI
To run a set of concurrent jobs, you will need to add a workflows section to your existing .circleci/config.yml file.
The simple example below shows the default workflow orchestration with two concurrent jobs. The workflows key needs to have a unique name. In this example, the unique name is build_and_test. The jobs key is nested under the uniquely named workflow, and contains the list of job names. Since the jobs have no dependencies, they will run concurrently.
version: 2.1
jobs:
build:
docker:
- image: cimg/<language>:<version TAG>
steps:
- checkout
- run: <command>
test:
docker:
- image: cimg/<language>:<version TAG>
steps:
- checkout
- run: <command>
workflows:
build_and_test:
jobs:
- build
- testGithub Actions
Offical documentation
concurrency:
group: ${{ github.ref }}
cancel-in-progress: trueJenkins
Offical documentation
def barrier = createBarrier count: 3;
boolean out = false;
parallel(
await1: {
awaitBarrier barrier
echo "out=${out}"
},
await2: {
awaitBarrier (barrier){
sleep 2 //simulate a long time execution.
}
echo "out=${out}"
},
await3: {
awaitBarrier (barrier){
sleep 3 //simulate a long time execution.
out = true
}
echo "out=${out}"
}
)Travis CI
Offical documentation
Say you want to split up your unit tests and your integration tests into two different build jobs. They’ll run in parallel and fully utilize the available build capacity for your account.
Here’s an example on how to utilize this feature in your .travis.yml:
env:
- TEST_SUITE=units
- TEST_SUITE=integrationThen you change your script command to use the new environment variable to determine the script to run.
script: "bundle exec rake test:$TEST_SUITE"Travis CI will determine the build matrix based on the environment variables and schedule two builds to run.